Proljetni protok podataka u oblaku s Apache Sparkom
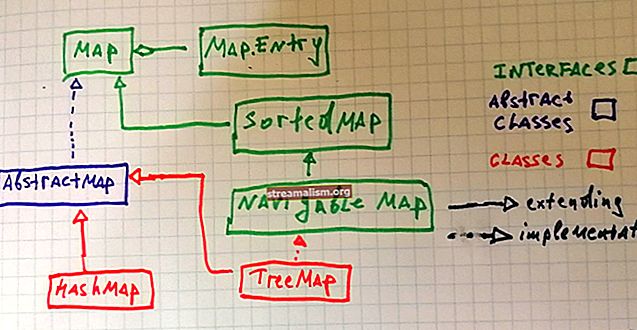
1. Uvod
Spring Cloud Data Flow alat je za izgradnju integracije podataka i cjevovoda za obradu podataka u stvarnom vremenu.
Cjevovodi su, u ovom slučaju, aplikacije Spring Boot koje su izrađene pomoću okvira Spring Cloud Stream ili Spring Cloud Task.
U ovom uputstvu pokazat ćemo kako koristiti Spring Cloud Flow Flow s Apache Sparkom.
2. Lokalni poslužitelj protoka podataka
Prvo, moramo pokrenuti poslužitelj protoka podataka kako bismo mogli rasporediti svoje poslove.
Da bismo lokalno pokrenuli poslužitelj protoka podataka, moramo stvoriti novi projekt s proljeće-oblak-starter-protok podataka-poslužitelj-lokalno ovisnost:
org.springframework.cloud proljeće-oblak-starter-protok podataka-poslužitelj-lokalno 1.7.4.OSPUSTI Nakon toga, glavnu klasu na poslužitelju moramo označiti s @EnableDataFlowServer:
@EnableDataFlowServer @SpringBootApplication javna klasa SpringDataFlowServerApplication {public static void main (String [] args) {SpringApplication.run (SpringDataFlowServerApplication.class, args); }}Jednom kada pokrenemo ovu aplikaciju, imat ćemo lokalni poslužitelj protoka podataka na portu 9393.
3. Izrada projekta
Stvorit ćemo Spark Job kao samostalnu lokalnu aplikaciju tako da nam za njegovo pokretanje neće trebati klaster.
3.1. Ovisnosti
Prvo ćemo dodati ovisnost Spark:
org.apache.spark spark-core_2.10 2.4.0 3.2. Stvaranje posla
A za naš posao, približimo pi:
javna klasa PiApproximation {javna statička void glavna (String [] args) {SparkConf conf = new SparkConf (). setAppName ("BaeldungPIApproximation"); JavaSparkContext context = novi JavaSparkContext (conf); int kriške = args.length> = 1? Integer.valueOf (args [0]): 2; int n = (100000L * kriške)> Integer.MAX_VALUE? Integer.MAX_VALUE: 100000 * kriški; Popis xs = IntStream.rangeClosed (0, n) .mapToObj (element -> Integer.valueOf (element)) .collect (Collectors.toList ()); JavaRDD dataSet = context.parallelize (xs, kriške); JavaRDD pointsInsideTheCircle = dataSet.map (integer -> {double x = Math.random () * 2 - 1; double y = Math.random () * 2 - 1; return (x * x + y * y) integer + integer2 ); System.out.println ("Pi je procijenjen na:" + count / n); context.stop (); }}4. Ljuska protoka podataka
Shell protoka podataka je aplikacija koja će omogućiti nam interakciju s poslužiteljem. Shell koristi DSL naredbe za opisivanje tokova podataka.
Da bismo koristili ljusku protoka podataka, moramo stvoriti projekt koji će nam omogućiti da ga pokrenemo. Prvo, trebamo proljetni-oblak-protok podataka-ljuska ovisnost:
org.springframework.cloud proljeće-oblak-protok podataka-ljuska 1.7.4.OBLAŽENJE Nakon dodavanja ovisnosti, možemo stvoriti klasu koja će izvoditi našu ljusku protoka podataka:
@EnableDataFlowShell @SpringBootApplication javna klasa SpringDataFlowShellApplication {public static void main (String [] args) {SpringApplication.run (SpringDataFlowShellApplication.class, args); }}5. Pokretanje projekta
Za implementaciju našeg projekta upotrijebit ćemo takozvani pokretač zadataka koji je dostupan za Apache Spark u tri verzije: Klastera, pređa, i klijent. Nastavit ćemo s lokalnim klijent verzija.
Pokretač zadataka je ono što pokreće naš posao Spark.
Da bismo to učinili, prvo moramo registrirajte naš zadatak pomoću ljuske protoka podataka:
registar aplikacija - tip zadatak --ime iskra-klijent --uri maven: //org.springframework.cloud.task.app: iskra-klijent-zadatak: 1.0.0.BUILD-SNAPSHOT Zadatak nam omogućuje da odredimo više različitih parametara, neki od njih nisu obvezni, ali neki od parametara potrebni su za pravilno postavljanje posla Spark:
- iskra.app-klasa, glavna klasa poslanog posla
- iskra.app-jar, put do staklenke masti koja sadrži naš posao
- iskra.app-Ime, ime koje će se koristiti za naš posao
- iskra.app-args, argumenti koji će se proslijediti poslu
Možemo koristiti registrirani zadatak iskra-klijent da prijavimo svoj posao, sjetimo se navesti potrebne parametre:
zadatak stvoriti spark1 --definition "spark-client \ --spark.app-name = my-test-pi --spark.app-class = com.baeldung.spring.cloud.PiApproximation \ --spark.app-jar = /apache-spark-job-0.0.1-SNAPSHOT.jar --spark.app-args = 10 "Imajte na umu da iskra.app-jar je put do masti sa našim poslom.
Nakon uspješnog stvaranja zadatka, možemo ga pokrenuti sljedećom naredbom:
iskra pokretanja zadatka1Ovo će pozvati izvršenje našeg zadatka.
6. Sažetak
U ovom smo uputstvu pokazali kako koristiti okvir Spring Cloud Data Flow za obradu podataka s Apache Sparkom. Više informacija o okviru Spring Cloud Data Flow možete pronaći u dokumentaciji.
Svi uzorci koda mogu se naći na GitHubu.