Brzo podudaranje uzoraka žica pomoću sufiksnog stabla u Javi
1. Pregled
U ovom uputstvu istražit ćemo koncept podudaranja uzoraka nizova i kako to možemo učiniti bržim. Zatim ćemo proći kroz njegovu implementaciju u Javi.
2. Usklađivanje uzoraka žica
2.1. Definicija
U nizovima je podudaranje uzorka postupak provjere određenog niza pozvanih znakova uzorak u nizu znakova koji se nazivaju a tekst.
Osnovna očekivanja podudaranja uzoraka kada uzorak nije regularni izraz su:
- podudaranje treba biti točno - ne djelomično
- rezultat bi trebao sadržavati sva podudaranja - ne samo prvo podudaranje
- rezultat bi trebao sadržavati položaj svake podudarnosti u tekstu
2.2. Traženje uzorka
Upotrijebimo primjer za razumijevanje jednostavnog problema s podudaranjem uzoraka:
Uzorak: NA Tekst: HAVANABANANA Match1: ---- NA ------ Match2: -------- NA-- Match3: ---------- NAMožemo vidjeti da je obrazac NA javlja se tri puta u tekstu. Da bismo dobili ovaj rezultat, možemo smisliti klizanje uzorka po tekstu jedan po jedan znak i provjeru podudaranja.
Međutim, ovo je grubi pristup s vremenskom složenošću O (p * t) gdje str je duljina uzorka i t je duljina teksta.
Pretpostavimo da imamo više obrazaca za traženje. Zatim se vremenska složenost također linearno povećava jer će svaki uzorak trebati zasebnu iteraciju.
2.3. Trie struktura podataka za pohranu uzoraka
Vrijeme pretraživanja možemo poboljšati pohranjivanjem uzoraka u strukturu podataka trie, koja je poznata po svom brzom retrieval predmeta.
Znamo da struktura podataka trie pohranjuje znakove niza u strukturu nalik stablu. Dakle, za dvije žice {NA, NAB}, dobit ćemo stablo s dvije staze:

Stvaranje trija omogućuje klizanje skupine obrazaca niz tekst i provjeru podudaranja u samo jednoj iteraciji.
Primijetimo da koristimo $ znak koji označava kraj niza.
2.4. Sufiks Trie struktura podataka za pohranu teksta
A sufiks trie, s druge strane, je trie struktura podataka konstruiran pomoću svih mogućih sufiksa pojedinog niza.
Za prethodni primjer HAVANABANANA, možemo konstruirati sufiks trie:

Pokušaji sufiksa stvaraju se za tekst i obično se izvode kao dio koraka predobrade. Nakon toga, pretraživanje uzoraka može se brzo obaviti pronalaženjem puta koji odgovara nizu uzoraka.
Međutim, poznato je da sufiksno troje troši puno prostora jer je svaki znak niza pohranjen u rubu.
U sljedećem ćemo odjeljku pogledati poboljšanu verziju sufiksa trie.
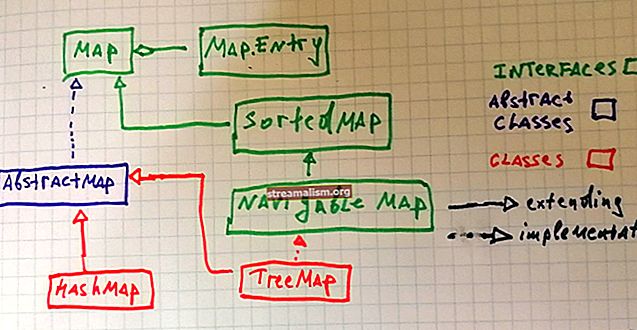
3. Sufiksno drvo
Sufiks stablo je jednostavno a stisnuti sufiks trie. To znači da spajanjem rubova možemo pohraniti skupinu znakova i time znatno smanjiti prostor za pohranu.
Dakle, možemo stvoriti stablo sufiksa za isti tekst HAVANABANANA:

Svaka staza koja započinje od korijena do lista predstavlja sufiks niza HAVANABANANA.
Sufiksno drvo također pohranjuje položaj sufiksa u čvoru lista. Na primjer, BANANA $ je sufiks koji počinje sa sedme pozicije. Stoga će njegova vrijednost biti šest pomoću numeriranja na temelju nule. Također, A-> BANANA $ je još jedan sufiks koji počinje na položaju pet, kao što vidimo na gornjoj slici.
Dakle, stavljajući stvari u perspektivu, to možemo vidjeti podudaranje uzorka događa se kada uspijemo dobiti stazu koja započinje od korijenskog čvora s rubovima koji se u potpunosti podudaraju s danim uzorkom u položaju.
Ako put završava na čvoru lista, dobit ćemo podudaranje sufiksa. U suprotnom, dobivamo samo podudaranje niza. Na primjer, uzorak NA je sufiks od HAVANABANA [NA] i podniz od HAVA [NA] BANANA.
U sljedećem ćemo odjeljku vidjeti kako implementirati ovu strukturu podataka u Javi.
4. Struktura podataka
Stvorimo strukturu podataka stabla sufiksa. Trebat će nam dvije klase domene.
Prvo, trebamo klasa koja predstavlja čvor stabla. Treba pohraniti rubove stabla i podređene čvorove. Osim toga, kada je to čvor lista, on treba spremiti pozicijsku vrijednost sufiksa.
Pa, kreirajmo svoje Čvor razred:
čvor javne klase {tekst privatnog niza; privatni popis djece; privatni int položaj; javni čvor (niz riječi, int položaj) {this.text = riječ; this.position = položaj; this.children = novi ArrayList (); } // getteri, postavljači, toString ()}Drugo, trebamo klasa koja predstavlja stablo i sprema korijenski čvor. Također treba pohraniti puni tekst iz kojeg se generiraju sufiksi.
Slijedom toga, imamo a SuffixTree razred:
javna klasa SuffixTree {private static final String WORD_TERMINATION = "$"; privatni statički konačni int POSITION_UNDEFINED = -1; korijen privatnog čvora; private String fullText; javno SuffixTree (tekst niza) {root = novi čvor ("", POSITION_UNDEFINED); fullText = tekst; }}5. Pomoćne metode za dodavanje podataka
Prije nego što napišemo svoju osnovnu logiku za pohranu podataka, dodajmo nekoliko pomoćnih metoda. Oni će se kasnije pokazati korisnima.
Izmijenimo svoj SuffixTree razreda dodati neke metode potrebne za konstrukciju stabla.
5.1. Dodavanje podređenog čvora
Prvo, imajmo metodu addChildNode do dodati novi podređeni čvor bilo kojem zadanom nadređenom čvoru:
private void addChildNode (čvor nadređeni čvor, tekst niza, int indeks) {nadimak.getChildren (). add (novi čvor (tekst, indeks)); }5.2. Pronalaženje najdužeg zajedničkog prefiksa dviju žica
Drugo, napisat ćemo jednostavnu korisnu metodu getLongestCommonPrefix do pronaći najduži zajednički prefiks dviju žica:
privatni niz getLongestCommonPrefix (niz str1, niz str2) {int compareLength = Math.min (str1.length (), str2.length ()); for (int i = 0; i <compareLength; i ++) {if (str1.charAt (i)! = str2.charAt (i)) {return str1.substring (0, i); }} return str1.substring (0, compareLength); }5.3. Dijeljenje čvora
Treće, imajmo metodu za izrezati podređeni čvor od određenog roditelja. U ovom procesu nadređeni čvor tekst vrijednost će se skratiti, a desno skraćeni niz postaje tekst vrijednost podređenog čvora. Uz to, djeca roditelja premjestit će se u podređeni čvor.
Na slici ispod to možemo vidjeti ANA se dijeli na A-> NA. Poslije novi sufiks ABANANA $ može se dodati kao A-> BANANA $:

Ukratko, ovo je praktična metoda koja će vam dobro doći pri umetanju novog čvora:
private void splitNodeToParentAndChild (Node parentNode, String parentNewText, String childNewText) {Node childNode = new Node (childNewText, parentNode.getPosition ()); if (parentNode.getChildren (). size ()> 0) {while (parentNode.getChildren (). size ()> 0) {childNode.getChildren () .add (parentNode.getChildren (). remove (0)); }} parentNode.getChildren (). add (childNode); parentNode.setText (nadređeniNewText); parentNode.setPosition (POSITION_UNDEFINED); }6. Pomoćna metoda za prelazak
Stvorimo sada logiku za prelazak stablom. Ovu ćemo metodu koristiti za izgradnju stabla i traženje uzoraka.
6.1. Djelomična utakmica naspram pune utakmice
Prvo, shvatimo koncept djelomičnog i potpunog podudaranja uzimajući u obzir stablo napunjeno s nekoliko sufiksa:

Da biste dodali novi sufiks ANABANANA $, provjeravamo postoji li čvor koji se može izmijeniti ili proširiti kako bi se prilagodio novoj vrijednosti. Zbog toga uspoređujemo novi tekst sa svim čvorovima i otkrivamo da postoji postojeći čvor [A] VANABANANA $ odgovara prvom znaku. Dakle, ovo je čvor koji trebamo izmijeniti i ovo se podudaranje može nazvati djelomičnim podudaranjem.
S druge strane, uzmimo u obzir da tražimo obrazac VANE na istom drvetu. Znamo da se djelomično podudara s [VAN] ABANANA $ na prva tri znaka. Da su se sva četiri znaka podudarala, mogli bismo to nazvati punim podudaranjem. Za pretragu uzoraka potrebno je potpuno podudaranje.
Dakle, da rezimiramo, koristit ćemo djelomično podudaranje pri konstruiranju stabla i potpuno podudaranje kada tražimo uzorke. Upotrijebit ćemo zastavu isAllowPartialMatch kako bismo naznačili kakvu vrstu podudaranja trebamo u svakom slučaju.
6.2. Prelazeći drvo
Sada, napišite svoju logiku da prelazimo stablo sve dok možemo pozicionirati zadani obrazac:
Popis getAllNodesInTraversePath (uzorak niza, Nod startNode, logička isAllowPartialMatch) {// ...}Nazvat ćemo to rekurzivno i vratiti popis svih čvorovi nalazimo na našem putu.
Počinjemo usporedbom prvog znaka teksta uzorka s tekstom čvora:
if (pattern.charAt (0) == nodeText.charAt (0)) {// logika za obradu preostalih znakova} Za djelomično podudaranje, ako je uzorak kraći ili jednak duljini tekstu čvora, dodajemo trenutni čvor u naš čvorovi popis i zaustavite se ovdje:
if (isAllowPartialMatch && pattern.length () <= nodeText.length ()) {nodes.add (currentNode); povratni čvorovi; } Zatim uspoređujemo preostale znakove teksta ovog čvora s uzorkom. Ako obrazac ima pozicijsku neusklađenost s tekstom čvora, ovdje se zaustavljamo. Trenutačni čvor uključen je u čvorovi popis samo za djelomično podudaranje:
int compareLength = Math.min (nodeText.length (), pattern.length ()); for (int j = 1; j <compareLength; j ++) {if (pattern.charAt (j)! = nodeText.charAt (j)) {if (isAllowPartialMatch) {nodes.add (currentNode); } povratni čvorovi; }} Ako se obrazac podudara s tekstom čvora, dodajemo trenutni čvor u naš čvorovi popis:
nodes.add (currentNode);Ali ako uzorak ima više znakova od teksta čvora, moramo provjeriti podređene čvorove. Zbog toga upućujemo rekurzivni poziv prolazeći currentNode kao početni čvor i preostali dio uzorak kao novi obrazac. Popis čvorova vraćenih iz ovog poziva dodan je našem čvorovi popis ako nije prazan. U slučaju da je prazan za scenarij punog podudaranja, to znači da je došlo do neusklađenosti, pa da bismo to naznačili, dodajemo a null artikal. I vraćamo čvorovi:
if (pattern.length ()> compareLength) {Popis čvorova2 = getAllNodesInTraversePath (pattern.substring (compareLength), currentNode, isAllowPartialMatch); if (nodes2.size ()> 0) {nodes.addAll (nodes2); } inače if (! isAllowPartialMatch) {nodes.add (null); }} povratni čvorovi;Sastavljajući sve ovo, stvorimo getAllNodesInTraversePath:
privatni popis getAllNodesInTraversePath (uzorak niza, čvor startNode, logički isAllowPartialMatch) {Čvorovi popisa = novi ArrayList (); for (int i = 0; i <startNode.getChildren (). size (); i ++) {Čvor currentNode = startNode.getChildren (). get (i); Niz nodeText = currentNode.getText (); if (pattern.charAt (0) == nodeText.charAt (0)) {if (isAllowPartialMatch && pattern.length () <= nodeText.length ()) {nodes.add (currentNode); povratni čvorovi; } int compareLength = Math.min (nodeText.length (), pattern.length ()); for (int j = 1; j compareLength) {Popis čvorova2 = getAllNodesInTraversePath (pattern.substring (compareLength), currentNode, isAllowPartialMatch); if (nodes2.size ()> 0) {nodes.addAll (nodes2); } inače if (! isAllowPartialMatch) {nodes.add (null); }} povratni čvorovi; }} povratni čvorovi; }7. Algoritam
7.1. Pohranjivanje podataka
Sada možemo napisati svoju logiku za pohranu podataka. Počnimo s definiranjem nove metode addSuffix na SuffixTree razred:
private void addSuffix (sufiks niza, int položaj) {// ...}Pozivatelj će odrediti položaj sufiksa.
Dalje, napišimo logiku za rukovanje sufiksom. Prvo, moramo provjeriti postoji li put koji se djelomično podudara sa sufiksom barem pozivom naše pomoćne metode getAllNodesInTraversePath s isAllowPartialMatch postaviti kao pravi. Ako ne postoji put, svoj sufiks možemo dodati kao dijete korijenu:
Popis čvorova = getAllNodesInTraversePath (uzorak, korijen, istina); if (nodes.size () == 0) {addChildNode (korijen, sufiks, pozicija); }Međutim, ako put postoji, to znači da moramo modificirati postojeći čvor. Ovaj čvor bit će posljednji u čvorovi popis. Također moramo shvatiti što bi trebao biti novi tekst za ovaj postojeći čvor. Ako je čvorovi Popis ima samo jednu stavku, tada koristimo sufiks. Inače, izuzmemo uobičajeni prefiks do zadnjeg čvora iz sufiks da biste dobili newText:
Čvor lastNode = nodes.remove (nodes.size () - 1); Niz newText = sufiks; if (nodes.size ()> 0) {String existingSuffixUptoLastNode = nodes.stream () .map (a -> a.getText ()) .reduce ("", String :: concat); newText = newText.substring (postojećiSuffixUptoLastNode.length ()); }Za modificiranje postojećeg čvora stvorimo novu metodu extensionNode, koju ćemo nazvati odakle smo stali addSuffix metoda. Ova metoda ima dvije ključne odgovornosti. Jedno je rastavljanje postojećeg čvora na roditelja i dijete, a drugo dodavanje djeteta na novostvoreni roditeljski čvor. Roditeljski čvor razbijamo samo da bismo ga učinili zajedničkim čvorom za sve njegove podređene čvorove. Dakle, naša nova metoda je spremna:
private void extensionNode (čvor čvora, niz newText, int pozicija) {String currentText = node.getText (); Niz commonPrefix = getLongestCommonPrefix (currentText, newText); if (commonPrefix! = currentText) {String parentText = currentText.substring (0, commonPrefix.length ()); Niz childText = currentText.substring (commonPrefix.length ()); splitNodeToParentAndChild (čvor, parentText, childText); } Niz preostaliTekst = newText.substring (commonPrefix.length ()); addChildNode (čvor, preostaliTekst, pozicija); }Sada se možemo vratiti našoj metodi za dodavanje sufiksa, koja sada ima svu logiku na mjestu:
private void addSuffix (sufiks niza, int pozicija) {Popis čvorova = getAllNodesInTraversePath (sufiks, korijen, istina); if (nodes.size () == 0) {addChildNode (korijen, sufiks, pozicija); } else {Čvor lastNode = nodes.remove (nodes.size () - 1); Niz newText = sufiks; if (nodes.size ()> 0) {String existingSuffixUptoLastNode = nodes.stream () .map (a -> a.getText ()) .reduce ("", String :: concat); newText = newText.substring (postojećiSuffixUptoLastNode.length ()); } extensionNode (lastNode, newText, pozicija); }}Napokon, izmijenimo naš SuffixTree konstruktor za generiranje sufiksa i pozivanje naše prethodne metode addSuffix da ih dodamo iterativno u našu strukturu podataka:
javna void SuffixTree (tekst niza) {root = novi čvor ("", POSITION_UNDEFINED); for (int i = 0; i <text.length (); i ++) {addSuffix (text.substring (i) + WORD_TERMINATION, i); } fullText = tekst; }7.2. Pretraživanje podataka
Nakon što smo definirali našu strukturu stabla sufiksa za pohranu podataka, sada možemo napisati logiku izvođenja pretraživanja.
Započinjemo dodavanjem nove metode searchText na SuffixTree razred, polaganje u uzorak za pretraživanje kao ulaz:
javni popis pretraživanjaTekst (uzorak niza) {// ...}Dalje, da provjerite je li uzorak postoji u našem sufiks stablu, nazivamo pomoćnom metodom getAllNodesInTraversePath s oznakom postavljenom samo za točno podudaranje, za razliku od dodavanja podataka kada smo dopuštali djelomična podudaranja:
Popis čvorova = getAllNodesInTraversePath (obrazac, korijen, netačno);Zatim dobivamo popis čvorova koji odgovaraju našem uzorku. Posljednji čvor na popisu označava čvor do kojeg se uzorak točno podudarao. Dakle, naš sljedeći korak bit će dobiti sve čvorove lista koji potječu iz ovog posljednjeg podudarajućeg čvora i dobiti položaje pohranjene u tim čvorovima lista.
Stvorimo zasebnu metodu getPositions uraditi ovo. Provjerit ćemo sprema li zadani čvor završni dio sufiksa da bismo odlučili treba li vratiti vrijednost njegove pozicije. I, to ćemo učiniti rekurzivno za svako dijete datog čvora:
privatni popis getPositions (čvor čvora) {Pozicije popisa = novi ArrayList (); if (node.getText (). ENDWith (WORD_TERMINATION)) {position.add (node.getPosition ()); } for (int i = 0; i <node.getChildren (). size (); i ++) {position.addAll (getPositions (node.getChildren (). get (i))); } povratne pozicije; }Nakon što imamo skup pozicija, sljedeći je korak pomoću njega označiti uzorke na tekstu koji smo pohranili u našem sufiks stablu. Vrijednost položaja označava gdje sufiks započinje, a duljina uzorka pokazuje koliko se znakova treba pomaknuti od početne točke. Primjenjujući ovu logiku, stvorimo jednostavnu korisnu metodu:
private String markPatternInText (Integer startPosition, String pattern) {String matchingTextLHS = fullText.substring (0, startPosition); String matchingText = fullText.substring (startPosition, startPosition + pattern.length ()); Niz podudaranjaTextRHS = fullText.substring (startPosition + pattern.length ()); vratiti matchTextLHS + "[" + matchingText + "]" + matchingTextRHS; }Sada imamo spremne metode podrške. Stoga, možemo ih dodati u našu metodu pretraživanja i upotpuniti logiku:
javni popis pretraživanjaTekst (uzorak niza) {Rezultat popisa = novi ArrayList (); Popis čvorova = getAllNodesInTraversePath (obrazac, korijen, netačno); if (nodes.size ()> 0) {Node lastNode = nodes.get (nodes.size () - 1); if (lastNode! = null) {Položaj popisa = getPositions (lastNode); position = position.stream (). sorted () .collect (Collectors.toList ()); position.forEach (m -> result.add ((markPatternInText (m, uzorak)))); }} vratiti rezultat; }8. Ispitivanje
Sad kad imamo svoj algoritam, testirajmo ga.
Prvo, pohranimo tekst u naš SuffixTree:
SuffixTree suffixTree = novo SuffixTree ("havanabanana"); Dalje, potražimo valjani obrazac a:
Popis podudaranja = suffixTree.searchText ("a"); match.stream (). forEach (m -> LOGGER.info (m));Pokretanje koda daje nam šest podudaranja kako se očekivalo:
h [a] vanabanana hav [a] nabanana havan [a] banana havanab [a] nana havanaban [a] na havanabanan [a]Dalje, idemo potražite drugi valjani obrazac nab:
Popis podudaranja = suffixTree.searchText ("nab"); match.stream (). forEach (m -> LOGGER.info (m)); Pokretanje koda daje nam samo jedno podudaranje kako se očekivalo:
hava [nab] ananaNapokon, krenimo potražite nevažeći obrazac nag:
Popis podudaranja = suffixTree.searchText ("nag"); match.stream (). forEach (m -> LOGGER.info (m));Pokretanje koda ne daje rezultate. Vidimo da mečevi moraju biti točni, a ne djelomični.
Dakle, naš algoritam pretraživanja uzoraka uspio je zadovoljiti sva očekivanja koja smo izložili na početku ovog vodiča.
9. Vremenska složenost
Prilikom konstrukcije sufiksnog stabla za zadani tekst duljine t, složenost vremena je O (t).
Zatim, za traženje uzorka duljine p,složenost vremena je O (p). Sjetite se da je to bilo za grubu pretragu O (p * t). Tako, pretraživanje uzoraka postaje brže nakon prethodne obrade teksta.
10. Zaključak
U ovom smo članku prvo razumjeli koncepte triju podatkovnih struktura - trie, sufiks trie i sufiks stablo. Tada smo vidjeli kako se sufiksno stablo može koristiti za kompaktno spremanje sufiksa.
Kasnije smo vidjeli kako koristiti stablo sufiksa za pohranu podataka i obavljanje pretraživanja uzoraka.
Kao i uvijek, izvorni kod s testovima dostupan je na GitHubu.